探索R中的数据结构
- 数据集的概念:
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。表2-1提供了一个假想的病例数据集。
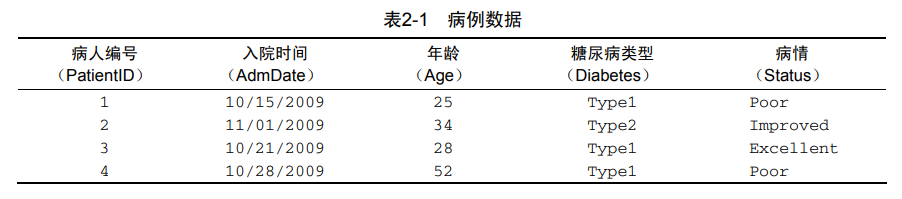
在表2-1所示的数据集中,PatientID是行/实例标识符,AdmDate是日期型变量,Age是连续型变量, Diabetes是名义型变量,Status是有序型变量。
R可以处理的数据类型(模式)包括数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)和原生型(字节)。
- 数据结构
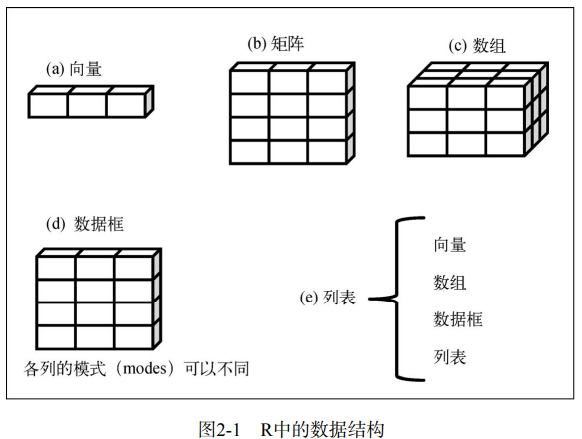
R中有许多用于存储数据的结构,包括标量、向量、数组、数据框和列表。
在R中,对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。
数据框(data frame)是R中用于存储数据的一种结构:列表示变量,行表示观测。在同一个数据框中可以存储不同类型(如数值型、字符型)的变量。数据框将是你用来存储数据集的主要数据结构。
因子(factor)是名义型变量或有序型变量。它们在R中被特殊地存储和处理。
- 2.1 向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()可用来创建向量
a <- c(1, 2, 3, 4, 5, 6)
b <-("one","two","three")
c <- c(TRUE,TRUE,TRUE,FALSE,TRUE,FALSE)
logic <- c(TRUE, FALSE, TRUE)
logic
## TRUE FALSE TRUE
这里,a是数值型向量,b是字符型向量,而c是逻辑型向量。注意:单个向量中的数据必须拥有相同的类型或模式(数值型、字符型或逻辑型)。同一向量中无法混杂不同模式的数据。
标量是只含一个元素的向量,例如f <- 3、g <- "US"和h <- TRUE。它们用于保存常量。
通过在方括号中给定元素所处位置的数值,我们可以访问向量中的元素。例如,a[c(2, 4)]
用于访问向量a中的第二个和第四个元素。
- 2.2 矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通
过函数matrix创建矩阵。
matrix函数会把这个向量中的值重新排列到一个矩阵之中。然后,使用参数 nrow 定义该矩阵的行
数。
dim(die) <- c(1, 2, 3, 4, 5, 6)
m <- matrix(die, nrow = 2)
m
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
matrix 函数默认的排列方式是先排满第一列再排第二列,并以此类推。你也可以将其排列方式改为按照行优先的
顺序进行排列,只需设置参数 byrow = TRUE 即可,如下所示。
m <- matrix(die, nrow = 2, byrow = TRUE)
m
## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
- 2.3 数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过array函数创建,形式如下:
ar <- array(c(11:14, 21:24, 31:34), dim = c(2, 2, 3))
ar
## , , 1
##
## [,1] [,2]
## [1,] 11 13
## [2,] 12 14
##
## , , 2
##
## [,1] [,2]
## [1,] 21 23
## [2,] 22 24
##
## , , 3
##
## [,1] [,2]
## [1,] 31 33
## [2,] 32 34
- 2.4 数据框
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。它与你通常在SAS、SPSS和Stata中看到的数据集类似。数据框将是你在R中最常处理的数据结构。
可以把数据框与 Excel 表格作对比,二者在数据的存储形式上很相似。
数据框可通过函数data.frame()创建:
mydata<- data.frame(col1,col2,col3,...)
其中的列向量col1, col2, col3,… 可为任何类型(如字符型、数值型或逻辑型)。每一列的
名称可由函数names指定
df <- data.frame(face = c("ace", "two", "six"),
suit = c("clubs", "clubs", "clubs"), value = c(1, 2, 3))
df
## face suit value
## ace clubs 1
## two clubs 2
## six clubs 3
- 2.5 因子
类别(名义型)变量和有序类别(有序型)变量在R中称为因子。函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1... k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
举例来说,假设有向量:
diabetes <- c("Type1","Type2","Type1","Type1")
语句diabetes <- factor(diabetes)将此向量存储为(1, 2, 1, 1),并在内部将其关联为
1=Type1和2=Type2(具体赋值根据字母顺序而定)。
你可以通过指定levels选项来覆盖默认排序。例如:
status <- factor(status,order=TRUE,
levels=c("Poor","Improved","Excellent"))
各水平的赋值将为1=Poor、2=Improved、3=Excellent
- 2.6 列表
列表(list)是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分,component)的有序集合。列表允许你整合若干(可能无关的)对象到单个对象名下。例如,某个列表中可能是若干向量、矩阵、数据框,甚至其他列表的组合。可以使用函数list()创建列表:
mylist <- list(object1, object2,...)
其中的对象可以是目前为止讲到的任何结构。你还可以为列表中的对象命名:
mylist <- list (name1=object1, name2=object2,...)
一下展示了一个例子
> g <- "My First List"
> h <- c(25,26,18,39)
> j <- matrix(1:10, nrow=5)
> k <- c( "one", "two", "three")
> my1ist <- list(title=g, ages=h, j, k)
> mylist
$tit1e
[1] "My First List"
$ages
[1] 25 26 18 39
[[3]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
[[4]]
[1] "one" "two" "three"
> mylist[[2]]
[1] 25 26 18 39
> mylist[["ages"]]
[1] 25 26 18 39
本例创建了一个列表,其中有四个成分:一个字符串、一个数值型向量、一个矩阵以及一个
字符型向量。可以组合任意多的对象,并将它们保存为一个列表。
你也可以通过在双重方括号中指明代表某个成分的数字或名称来访问列表中的元素。此例
中,mylist[[2]]和mylist[["ages"]]均指那个含有四个元素的向量。
3 数据的输入
R可从键盘、文本文件、Microsoft Excel和Access、流行的统计软件、特殊格
式的文件,以及多种关系型数据库中导入数据。
3.1 使用键盘输入数据
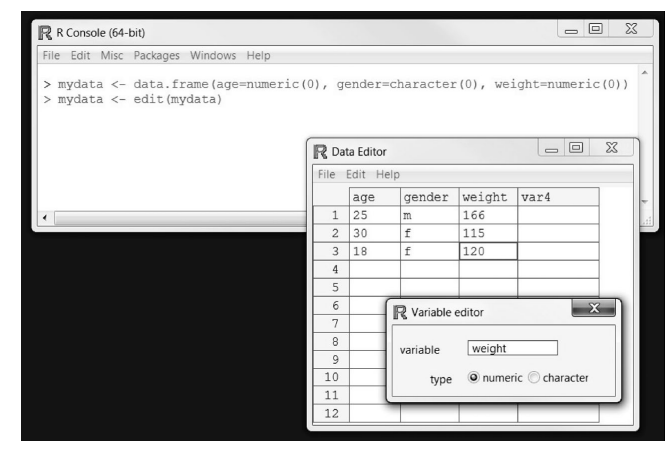
R中的函数edit()会自动调用一个允许手动输入数据的文本编辑器
mydata <- data.frame(age=numeric(0),gender=character(0), weight=numerie(0))
mydata <- edit(mydata)
3.2 从带分隔符的文本文件导入数据
你可以使用read.table()从带分隔符的文本文件中导入数据。此函数可读入一个表格格式的文件并将其保存为一个数据框。
mydataframe <- read.table(file, header=logical_value,sep="delimiter", row.names="name")
上述代码file是一个带分隔符的ASCII文本文件,header是一个表明首行是否包含了变量名的逻
辑值(TRUE或FALSE),sep用来指定分隔数据的分隔符,row.names是一个可选参数,用以指
定一个或多个表示行标识符的变量。
grades <- read.table("studentgrades.csv", header=TRUE, sep=",",
row.names="STUDENTID")
上述代码从当前工作目录中读入了一个名为studentgrades.csv的逗号分隔文件,从文件的第一行取得
了各变量名称,将变量STUDENTID指定为行标识符,最后将结果保存到了名为grades的数据框中。
默认情况下,字符型变量将转换为因子。我们并不总是希望程序这样做(例如处理一个含有被调查者评 论的变量时)。有许多方法可以禁止这种转换行为。其中包括设置选项stringsAsFactors=FALSE,这将停止对所有字符型变量的此种转换。
3.3 导入Excel数据
在Windows系统中,你也可以使用RODBC包来访问Excel文件。
首先,下载并安装RODBC包。
install.packages("RODBC")
你可以使用以下代码导入数据:
library(RODBC)
channel <- odbcConnectExcel("myfile.xls")
mydataframe <- sqlFetch(channel,"mysheet")
odbeClose(channel)
上述代码中myfile.xls是一个Excel文件,mysheet是要从这个工作簿中读取工作表的名称,
channel是一个由odbcConnectExcel()返回的RODBC连接对象,mydataframe是返回的数据
框。RODBC也可用于从Microsoft Access导入数据。
另外xlsx包可以用来读取电子表格。下载并安装好后。包中的函数read.xlsx()可将XLSX文件中的工作表导入为一个数据框。其最简单的调用格式是read.xlsx(file, n),其中file是Excel 2007工作簿的所在路径,n则为要导入的工作表序号。
举例说明,在Windows上,以下代码:
library(xlsx)
workbook <- "e:/myworkbook.x1sx"
mydataframe <- read.xlsx(workbook,1)
3.4 导入XML数据
R中有若干用于处理XML文件的包。例如,由Duncan Temple Lang编写的XML包允许用户读取、写入和操作XML文件。
3.5 从网页抓取数据
在Web数据抓取(Webscraping)的过程中,用户从互联网上提取嵌入在网页中的信息,并将其保存为R中的数据结构以做进一步的分析。完成这个任务的一种途径是使用函数readLines()下载网页,然后使用如grep()和gsub()一类的函数处理它。对于结构复杂的网页,可以使用RCurl包和XML包来提取其中想要的信息。
3.6 导入SPSS数据
SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc包中的spss.get()函数。
3.6 导入SAS数据
R中设计了若干用来导入SAS数据集的函数,包括foreign包中的read.ssd()和Hmisc包中的sas.get()。
也可以在SAS中使用PROC EXPORT将SAS数据集保存为一个逗号分隔的文本文件,并使用3.2节中叙述的方法将导出的文件读取到R中。
SAS程序:
proc export data=mydata
outfile="mydata.csv"
dbms=csv;
run
R程序
mydata <- read.table("mydata.csv",header=TRUE,sep=",")
3.8 导入Stata数据
要将Stata数据导入R中非常简单直接。所需代码类似于:
library(foreign)
mydataframe <- read.dta("mydata.dLa")
这里,mydata.dta是Stata数据集,mydataframe是返回的R数据框。
4 数据集的标注
数据集标注包括为变量名添加描述性的标签,以及为类别型变量中的编码添加值标签。
4.1 变量标签
将变量标签作为变量名,然后通过位置下标来访问这个变量。
names (patientdata)[2] <- "Age at hospitalization (in years)
将age重命名为"Age at hospitalization (in years)"。很明显,新的变量名太长,不适合重复输入。作为替代,你可以使用patientdata[2]来引用这个变量,而在本应输出age的地方输出字符"Age at hospitalization (in years)"。
4.2 值标签
函数factor()可为类别型变量创建值标签
patientdata$gender <- factor (patientdatasgender,
levels = e(1,2),
labels = c("male", "female"))
这里levels代表变量的实际值,而labels表示包含了理想值标签的字符型向量。
5.处理数据对象的实用函数
| 函 数 | 用 途 |
|---|---|
| length(object) | 显示对象中元素/成分的数量 |
| dim(object) | 显示某个对象的维度 |
| str(object) | 显示某个对象的结构 |
| class(object) | 显示某个对象的类或类型 |
| mode(object) | 显示某个对象的模式 |
| names(object) | 显示某对象中各成分的名称 |
| c(object, object,…) | 将对象合并入一个向量 |
| cbind(object, object, …) | 按列合并对象 |
| rbind(object, object, …) | 按行合并对象 |
| Object | 输出某个对象 |
| head(object) | 列出某个对象的开始部分 |
| tail(object) | 列出某个对象的最后部分 |
| ls() | 显示当前的对象列表 |
| rm(object, object, …) | 删除一个或更多个对象。语句rm(list = ls()) 将删除当前工作环境中的几乎所有对象* |
| newobject <- edit(object) | 编辑对象并另存为newobject |
| fix(object) | 直接编辑对象 |
head(patientdata)将列出数据框的前六行,而tail(patientdata)将列出最后六行


文章评论