NONMEM软件可通过自定义方式,高度灵活地建立各种复杂的药动学药效学模型。 NONMEM软件中既有内设的药动学模型(ADVAN1、ADVAN2、ADVAN3、ADVAN4、 ADVAN10、ADVA、ADVAN11和ADVAN12),也可采用非限定的PRED及PREDPP模块,自由定义房室数目、参数和相关函数关系式等,描述复杂的药动学和药效学行为。例如, 零级和一级的混合吸收、渐进吸收、非线性消除、自身诱导等。这些特殊药动学行 为难以用NONMEM内置的ADVAN模块直接进行表征。
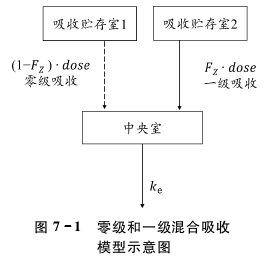
下图表征了某一级消除的一房室模型药物的 药动学模型结构。该药具有一级和零级动力学的混合吸收特征。参数FZ指经一级速率吸收药物的分 数,1-FZ指经零级速率吸收药物的分数,Ke指一级消除速率常数。
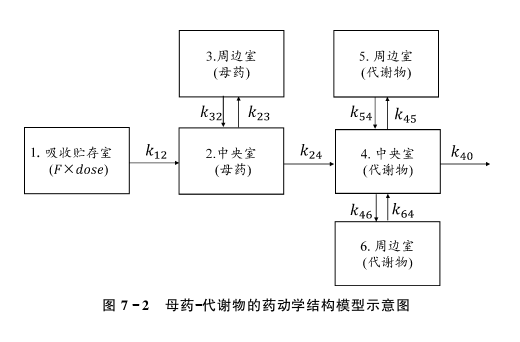
下图描述了含代谢产物的药动学模型,该药的药动学模型含6个房室,母药为两房室模型,代谢物为三房室模型。母药和代谢物在各房室间的转运为线性动力学过程。NONMEM的自定义模块可用于描述原药和代谢物的转运过程,进而拟合估算药动学参数。
自定义模型时,须定义模型的房室结构、参数、各房室间物质转运的数学关系式 等。除了编写控制文件外,还常须对数据集作相应的调整。
常用模块
一 、$PRED
因变量(y)和自变量(x)具有直接数学函数关系,因而可使用PRED模块对其函数关系式直接描述,进而估算模型参数。在药动学建模中,PRED模块可用于线性回归或非 线性回归模型的构建。PRED模块也可用于建立药效学模型,如最大效应模型描述药效 指标随治疗时间的变化过程;又如线性模型描述药效学与药动学的关系等。
二、PREDPP子程序
PREDPP子程序中ADVAN5、ADVAN6、ADVAN7、ADVAN8、ADVAN9和ADVAN13可 实现用户自定义模型。其中ADVAN5和ADVAN7以线性模型描述药物在不同房室间的 转运,ADVAN6、ADVAN8、ADVAN9、ADVAN13以自定义微分方程形式描述药物在不同房 室间的转运。下面将分别介绍。
$MODEL
$MODEL定义模型房室数量和属性,以COMP语句命名各房室并定义其属性。
$MODEL
COMP(DEPOT, DEFDOS) ;定义吸收室,DEFDOS:default doseing compartment
COMP(CENTRAL, DEFOBS) ;定义中央室,DEFOBS:default observation compartment
COMP(PeripheralSHALLOW) ;定义周边室,浅
COMP(PeripheralDEEP) ;定义周边室,深
房室的命名可以用NONMEM术语之外的任意字母数字。一般推荐采用具有实际意义的命名,便于更好地理解模型的结构。如上述代码中,DEPOT,CENTRAL,PeripheralSHALLOW,PeripheralDEEP
上述代码中, DEFDOS(defaultdosingcompartment)和DEFOBS(defaultobservation compartment)是NONMEM术语,分别指默认的给药室和观测室(血药浓度或药效指标等),不可更改。此外,须在数据集中同时定义CMT项,并与DEFDOS,和DEFOBS项中房 室的定义保持一致。
$SUBROUTINES
定义房室的数学关系,指定数学关系子程序。模型的数学解析算法由ADVAN子程序指定。房室间物质转运的关系通常由PK DES 和 ERROR模块中的参数和方程来定义。
- 通用线性模型
ADVAN5和ADVAN7:通用线性模型可用于描述由一级速率转运的房室模型,其优势在于计算速度快。当速率常数矩阵的特征值为实数时(如大多数药动学结构),可采用ADVAN7进行计算。一般情况下,ADVAN7的运算速度比ADVAN5快。
应用ADVAN5和ADVAN7时,须在 MODEL模块中定义房室数量,并在$PK模块中 定义房室间的药物转运。房室之间的转运可用一级速率常数k表示。k后面的数字代表房室间的转运,如k12定义从房室1到房室2的一级动力学转运,前1个数字是来源室, 后1个数字是目标室。当模型多于9个房室时,房室号增加至两位数。此时,数字间应用大写字母T分隔。如从房室1到房室10的转运应编码为k1T10。药物从体内消除的房室用 0编码,0为输出室,如K20表示药物从房室2以一级速率清除至体外。
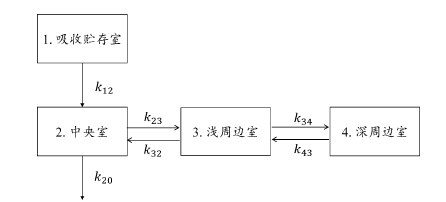
若采用具生理意义的药动学参数,如清除率和分布容积时,可通过CL/V等公式定义k。如图所示的具有一级吸收的三室模型的药物,可用以下代码描述其药动学行为。
示例代码:
$PROBLEM 3 CMT
$INPUT ID TIME AMT DV CMT EVID MDV
$DATA 7-1.csv IGNORE=#
$SUBROUTINES ADVAN5
$MODEL
COMP(DEPOT, DEFDOS)
COMP(CENTRAL, DEFOBS)
COMP(PeripheralSHALLOW)
COMP(PeripheralDEEP)
$PK
;定义清除率和分布容积相关参数
KA = THETA(1)
V2 = THETA(2) * EXP(ETA(1))
CL = THETA(3) * EXP(ETA(2))
Q1 = THETA(4)
Q2 = THETA(5)
V3 = THETA(6)
V4 = THETA(7)
; 定义ADVAN 5 & 7 的速率常数
K12 = KA
K20 = CL/V2
K23 = Q1/V2
K32 = Q1/V3
K34 = Q2/V3
K43 = Q2/V4
$ERROR
IPRED = F
Y = F * (1+ERR(1))
IRES = DV - IPRED
DEL = 0
IF (DV .EQ. 0) DEL=1
IWRES = (1-DEL) * IRES / (DV + DEL)
$THETA
(0,0.3) ;KA
(0,1.63) ;V2
(0,0.978) ;CL
15 FIXED ;Q1
10 FIXED ;Q2
40 FIXED ;V3
60 FIXED ;V4
$OMEGA
0.25 ;BSV_V2
0.25 ;BSV_CL
$SIGMA
0.16 ;ERR1
$ESTIMATION METH=1 INTE MAXEVAL=9999 PRINT=20 NOABORT
$COVARIANCE PRINT=E
$TABLE ID TIME AMT DV CMT EVID MDV DV IPRED PRED NOHEADER NOPRINT NOAPP FILE=7-1.fit
- 通用非线性模型
模块:ADVAN6、ADVAN8、ADVAN9、ADVAN13、ADVAN8。通过微分方程描述模型特征,还需要定义计算的精确度TOL
ADVAN6、ADVAN8、ADVAN9和ADVAN13间的主要区别在于微分方程的求解算法 不同。ADVAN6和ADVAN8针对刚性与非刚性微分方程进行了优化,ADVAN9和 ADVAN13使用了其他算法求解微分方程。上述模块中,ADVAN6的运算速度常最快,适用 于大多数情况;ADVAN9则更为稳健,有时优于ADVAN6。对于结构复杂的模型,NONMEM 创始人StuartBeal提供了一种选择最佳ADVAN模块的方法。首先,为每个待比较的ADVAN模块编写控制文件,在ESTIMATION模块中加入ESTIMATION MAXEVAL=1, 使每个ADVAN仅作一次迭代估算,然后分别运行,比较每种ADVAN的计算输出速度。 最快给出第一次迭代结果的ADVAN模块是首选方法。 -
$DES
$DES模块包含一系列微分方程组,每个房室均有一个方程,表征房室中瞬时质量、 浓度或效应量的变化率。此外,房室中物质的转运变化须符合物料平衡原理。
微分方程组用DADT(i)表示,其中i是定义的房室数。以经典的一级口服吸收和一 级消除的两房室模型为例,胃肠道室(房室1)、中央室(房室2)、周边室(房室3)药物量的 变化,可用如下微分方程表征:$\frac{d A(1)}{d t}=-k_{\mathrm{a}} \times A(1)$
$\frac{d A(2)}{d t}=k_4 \times A(1)-\left(k_{23}+k_{20}\right) \times A(2)+k_{32} \times A(3)$
$\frac{d A(3)}{d t}=k_{23} \times A(2)-k_{32} \times A(3)$
在NONMEM中的代码为:
$$
\begin{aligned}
& \operatorname{DADT}(1)=-K A * A(1) \
& \text { DADT (2) }=\mathrm{KA} * A(1)-(\mathrm{K} 23+\mathrm{K} 20) * A(2)+\mathrm{K} 32 * A(3) \
& \operatorname{DADT}(3)=\quad \mathrm{K} 23 \quad * \mathrm{~A}(2)-\mathrm{K} 32 * \mathrm{~A}(3) \
&
\end{aligned}
$$
A(n)是t时刻房室n中的药物的量,KA是吸收速率常数,K20是一级消除速率 常数,K23和K32是房室间转运的一级速率常数。KA、K23、K32和K20是固定效应参数,须在PK或DES模块中定义,并在THETA(模块中赋予初始值。此外,须注意本例中参数定义与传统参数定义不同。如中央室到周边室的速率常数为k23,而通常定义为k12。
典型示例
一、多元线性回归
二、零级和一级的混合吸收
- 已定义吸收分数
$PROBLEM example3
$DATA 7-3.csv IGNORE=#
$INPUT ID TIME DV AMT EVID RATE MDV CMT
$SUBROUTINES ADVAN6 TOL=3
$MODEL ;定义模型的房室结构
COMP (DEPOT1,DEFDOS)
COMP (CENTRAL,DEFOBS)
$PK
KA = THETA(1)*EXP(ETA(1)) ;一级吸收速率常数
ALAG2 = 2 ;零级吸收时滞
D2 = THETA(2) ;零级吸收输注时间
CL = THETA(3)*EXP(ETA(2)) ;中央室清除率
V = THETA(4) ;中央室分布容积
K = CL/V ;消除速率常数
S2 = V
$DES
DADT(1) = -A(1)*KA ;房室1的药量
DADT(2) = A(1)*KA-A(2)*K ;房室2的药量
$ERROR
IPRED = F
Y = F*(1+ERR(1))
$THETA
(0,1) ;KA
(0,2) ;D2
(0,10) ;CL
(0,20) ;V
$OMEGA
0.09 ;BSV_KA
0.09 ;BSV_CL
$SIGMA
0.16 ;ERR1
$ESTIMATION METH=1 MAXEVAL=9999 PRINT=20 NOABORT
$COVARIANCE PRINT=E
$TABLE ID TIME DV AMT EVID RATE MDV CMT IPRED PRED NOHEADER NOPRINT NOAPP FILE=7-3.fit
- 未定义吸收分数
$PROBLEM Parallel first-order and zero-Order Abs.
$DATA 7-4.csv IGNORE=#
$INPUT ID TIME DV AMT EVID RATE MDV CMT
$SUBROUTINES ADVAN2; TRANS2
$PK
;定义清除率和分布容积相关参数
F1 = THETA(1) ;经一级吸收途径药物的分数
F2 = 1-F1 ;经零级吸收药物的分数
ALAG2 = THETA(2) ;零级吸收时滞
D2 = THETA(3) ;零级吸收输注时间
KA = THETA(4) ;一级吸收速率常数
TVV = THETA(5)
V = TVV * EXP(ETA(1)) ;中央室分布容积
TVK = THETA(6)
K = TVK * EXP(ETA(2)) ;消除速率常数
S2 = V/1000 ;DOSE=mg;DV=ng/ml
$ERROR
IPRED = F
Y = F*(1+EPS(1))
$THETA
(0,0.2) ;F1
2 FIXED ;ALAG2
(0,2) ;D2
(0,1) ;KA
(0,20) ;V
(0,0.5) ;K
$OMEGA
0.09 ;BSV_V
0.09 ;BSV_CL
$SIGMA
0.16 ;ERR1
$ESTIMATION METH=1 MAXEVAL=9999 PRINT=20 NOABORT
$COVARIANCE PRINT=E
$TABLE ID TIME DV AMT EVID RATE MDV CMT IPRED PRED NOHEADER NOPRINT NOAPP FILE=7-4.fit
$PROBLEM Parallel first-order and zero-Order Abs.
$DATA 7-5.csv IGNORE=#
$INPUT ID TIME DV AMT EVID RATE MDV CMT
$SUBROUTINES ADVAN6 TOL=4
$MODEL ;定义模型的房室结构
COMP (DEPOT1,DEFDOS)
COMP (CENTRAL,DEFOBS)
$PK
;定义清除率和分布容积相关参数
F1 = THETA(1) ;经一级吸收途径药物的分数
F2 = 1-F1 ;经零级吸收药物的分数
ALAG2 = THETA(2) ;零级吸收时滞
D2 = THETA(3) ;零级吸收输注时间
KA = THETA(4) ;一级吸收速率常数
TVV = THETA(5)
V2 = TVV * EXP(ETA(1)) ;中央室分布容积
TVK = THETA(6)
K = TVK * EXP(ETA(2)) ;消除速率常数
S2 = V2/1000 ;DOSE=mg;DV=ng/ml
$DES
DADT(1) = -A(1)*KA ;房室1的药量
DADT(2) = A(1)*KA-A(2)*K ;房室2的药量
$ERROR
IPRED = F
Y = F*(1+ERR(1))
$THETA
(0,0.2) ;F1
2 FIXED ;ALAG2
(0,2) ;D2
(0,1) ;KA
(0,20) ;V
(0,0.5) ;K
$OMEGA
0.09 ;BSV_V
0.09 ;BSV_CL
$SIGMA
0.16 ;ERR1
$ESTIMATION METH=1 MAXEVAL=9999 PRINT=20 NOABORT
$COVARIANCE PRINT=E
$TABLE ID TIME DV AMT EVID RATE MDV CMT IPRED PRED NOHEADER NOPRINT NOAPP FILE=7-5.fit
三、母药和代谢物
$PROBLEM Model of Parent and Metabolite
$DATA 7-6.csv IGNORE=#
$INPUT ID TIME DV AMT EVID MDV CMT
$SUBROUTINES ADVAN6 TOL=4
$MODEL
COMP(DEPOT, DEFDOS)
COMP(PARE,DEFOBS)
COMP(METB)
$PK
;定义清除率和分布容积相关参数
V2 = THETA(1) *EXP(ETA(1))
KA = THETA(2)
VMAX = THETA(3)
KM = THETA(4)
K30 = THETA(5) *EXP(ETA(2))
V3 = THETA(6)
S2 = V2/1000
S3 = V3/1000
$DES
DADT(1) = -A(1)* KA
DADT(2) = A(1)* KA- (VMAX*A(2))/(KM+A(2))
DADT(3) = -A(3)* K30 + ((VMAX*A(2))/(KM+A(2)))
$ERROR
IPRED = F
IF(CMT.EQ.2) TYPE=0 ;母药
IF(CMT.EQ.3) TYPE=1 ;代谢物
Y = (F*EXP(EPS(1)))*(1-TYPE)+ (F*EXP(EPS(2)))*TYPE ;比例残差模型
$THETA
(0,10) ;V2
(0,2) ;KA
(0,10) ;VMAX
(0,5) ;KM
(0,1) ;K30
(0,10) ;V3
$OMEGA
0.09 ;BSV_K20
0.09 ;BSV_V2
$SIGMA
0.16 ;EPS1
0.16 ;EPS2
$ESTIMATION METH=1 INTE MAXEVAL=9999 PRINT=20 NOABORT
$COVARIANCE PRINT=E
$TABLE ID TIME DV AMT EVID MDV CMT IPRED PRED NOHEADER NOPRINT NOAPP FILE=7-6.fit


文章评论