NONMEN 控制文件简介
构建群体药动学药效学模型及估算参数时,须建立特定格式的控制文件。
控制文件是ASCII文本文件,可采用微软的记事本等文本编辑程序进行编写。 控制文件由一系列命令行构成。每一条命令行或模块的起始以特定字符美元字符“$”开头。 此外,命令或模块名可使用完整名或前4个字符的缩写,如PROBLEM可用PROB代替。
NONMEN 控制文件组成
每一条命令行或者模块以特定符号“$”开头,可缩写
控制文件主要由PROBLEM、DATA、INPUT、PRED、THETA、OMEGA、SIGMA、ESTIMATION、TABLE等模块组成。
一、$PROBLEM模块
控制文件的第一条命令行,为必需项,描述文件的信息,作为控制文件的标题或者注释
$PROB 3cp_PK
二、$DATA模块
指定所需数据文件及读取路径,后面和附加选项 IGNORE:指定数据文件的路径和名称;IGNORE=#,IGNORE=C 代表数据行中第一个字符是#或C时,该数据行将不被 NMTRAN纳入计算.
$DATA infusion_3cp.csv IGNORE=C
IGNORE还可以指定特定数据:
$DATA infusion_3cp.csv IGNORE= (AGE.LT.12)
FORTRAN 常用的判断逻辑
==或.eq. 判断是否相等
/=或.ne. 判断是否不等
>或.gt. 判断是否大于
>=或 .ge. 判断是否大于等于
<或.lt. 判断是否小于
<=或.le. 判断是否小于等于
IGNORE还可以增加条件选项,如:
$DATA infusion_3cp.csv IGNORE=C IGNORE= (AGE.LT.12)
$DATA infusion_3cp.csv IGNORE=C ACCEPT= (WK.GT.40,AGE.GT.12)纳入体重>40kg或者年龄≥12岁的患者
纳入体重>40kg或者年龄≥12岁的患者
三、$INPUT模块
指定数据文件的数据结构。模块定于的变量顺序需和数据文件的每列
$INPUT C ID TIME TAD NMT CONC=DV AMT RATE MDV DOSE GROUP sex=DROP age weight height bmi
CONC=DV
表示用CONC取代保留变量DV 即为CONC为药代动力学浓度的观测值
sex =DROP
表示忽略改变量
四、$SUBROUTINES模块
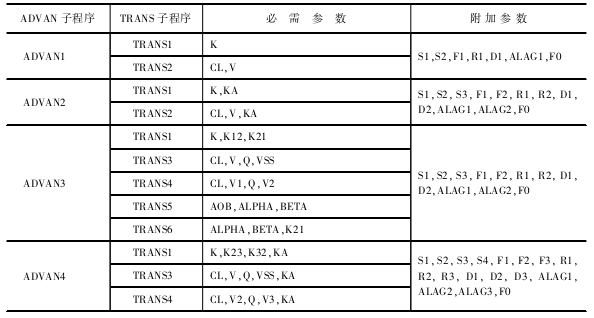
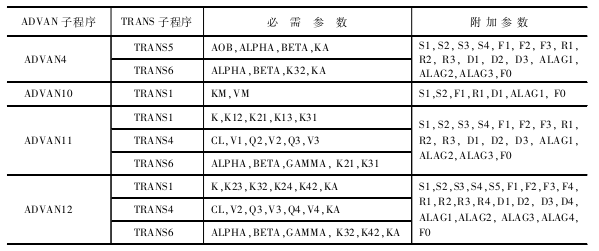
$SUBROUTINES用于确定调用哪种子程序。,包括特定的ADVAN子程序和 TRANS子程序。ADVAN指定何种药动学房室模型,TRANS指定模型的基本药动学参数, 每个子程序均附加数字标识。
ADVAN指定房室模型种类
TRANS指定基本药动学参数
ADVAN1-4、10-12是内置的药动学模型,分别指一室静脉、一室口服、二室静脉、二室口服、米氏模型、三室静脉、三室口服。选择了以上的ADVAN子程序后,还需选择相应的TRANS子程序。
如:
$SUBROUTINES ADVAN11 TRANS4
ADVAN和TRANS所需的参数表:
五、$PK模块
ADVAN和TRANS所需的必须参数和附件参数,$PK模块指定这些参数的典型值和体间变异。
定义参数:
TVCL = THETA(1)
定义体间变异和类型:
CL = TVCL +ETA(1) ;加和型
CL = TVCL * (1+ETA(1)) ;比例型
CL = TVCL * EXP(ETA(1)) ;指数型
以TV开头的变量名表示参数的典型值,如TVCL表示清除率的典型值,CL表示特定的个体值。
如:
$PK
TVCL=THETA(1)
CL=TVCL*EXP(ETA(1))
TVV1=THETA(2)
V1=TVV1*EXP(ETA(2))
TVV2=THETA(3)
V2=TVV2*EXP(ETA(3))
TVQ2=THETA(4)
Q2=TVQ2*EXP(ETA(4))
TVV3=THETA(5)
V3=TVV3*EXP(ETA(5))
TVQ3=THETA(6)
Q3=TVQ3*EXP(ETA(6))
附加参数定义
TVALAG1=THETA(7)
ALAG1=TVALAG1*EXP(ETA(7))
IF= (DOSE.GT.3) F1=1
IF= (DOSE.LT.3) F1=THETA(8)
定义换算系数
定义 Sn 可使给药量和药物浓度单位纲保持一致。 n表示观测事件发生的隔室, Sn 表示分布容积和无单位标量值得乘积:
$$
S_n = V ×usv
$$
$$
C_n = \frac{amount}{S_n} = \frac{amount}{V ×usv}
$$
如:给药剂量为mg,分布体积单位为L,浓度观测单位为ng/ml则
$$
C_n = \frac{mg}{L×usv} = \frac{ng}{ml}
$$
此时:$usv$ =1000
S1=V1/1000
S2=V2/1000
S3=V3/1000
IF语句应用
选择结构语句
if (logical expression) then
statement(s)
else
other_statement(s)
end if
嵌套选择结构语句
if (logical expression) then
statement(s)
elseif (logical expression2) then
statement2(s)
elseif (logical expression3) then
statement3(s)
······
other_statement(s)
end if
示例:
IF (RATE.EQ.1) THEN
F1=1
ELSE
F1=THETA(1)
ENDIF
六、$ERROR模块
描述预测值F与实测值Y的差异,称为残差变异。
简单残差变异模型:加和型,比例型,指数型,结合型
$ERROR
IPRED=F ;individual prediction
Y=F*+EPS(1) ;加和型
Y=F*(1+EPS(1)) ;比例型
Y=F*EXP(EPS(1)) ;指数型
Y=F*(1+ERR(1))+ERR(2) ;结合型
简单残差变异模型:考虑了不同分析方法
七、$PRED模块
$PRED模块用于不需要调用PREDPP子程序的模型,位于 DATA和 INPUT 之后,代替了SUBROUTINES、PK和 ERROR模块。参数(包括个体间变异)、表达式、残差模型完全自己定义,变量可任意命名。*
$PRED
A=THETA(1)*EXP(ETA(1))
B=THETA(2)
EFF=A*CMAX+B
Y=EFF*(1+EPS(1))
$THETA
(1 FIXED) ;KA
(0,5) ;CL
(0,60) ;V
$OMEGA
0.09 ;BSV of CL
0.09 ;BSV of V
$SIGMA
0.09 ;RV
八、THETA、OMEGA、 SIGMA模块
用于设定参数的初值,上下限,以及固定参数。
$THETA(下限,初值,上限)
$THETA(0,45,100)
$THETA(45 FIX) ;固定
$OMEGA
(0.09 FIX) ;OMEGA1
0.09 ;OMEGA2
0.09 ;OMEGA3
$SIGMA
0.09 ;add
0.02 ;eps
九、 ESTIMATION、 COVARIANCE模块
$ESTIMATION
METHOD指定估计方法,MAXEVAL指定最大迭代次数,PRINT指定每多少次运算输出一次结果,$SIGDIGITS模块指定有效数字位数。
$EST METHOD=1 INTER NOABORT PRINT=5 MAX=9999 SIG=3
NONMEN 估算方法:
1. 一阶估算法(FO)
2. 一阶条件估算法(FOCE)
3. 含个体间变异-残差变异交互作用的一阶条件估算法(FOCE-I)
4. 拉普拉斯法(LAPL)
5. 最大期望算法(EM),包括:
6. 蒙特卡洛重要抽样法(IMP)
7. 基于后验估计的重要抽样法(IMPMAP)
8. 随机渐进最大期望法(SAEM)
9. 马尔科夫链蒙特卡洛贝叶斯法(MCMC)
10. 迭代两步法(ITS)
$COVARIANCE模块对估计结果进行协方差分析。MATRIX指定估计R矩阵还是S矩阵,PRINT=E指定输出方差-协方差矩阵的特征值。
$COVARIANCE MATRIX=R PRINT=E CONDITIONAL
十、TABLE、 SCATTERPOL模块
$TABLE 以指定的文本形式输出模型参数结果
- NOAPPEND指定不输出观测值(DV)、群体预测值(PRED)、残差(RES)、加权残差(WRES),默认输出
- NOPRINT指定不在.lst文件里输出数据列表;
- FILE指定结果输出的文件名;
- ONEHEADER指定列名只出现在第一行。
$SCATTERPOL模块输出绘制散点图的数据


文章评论